Das Betriebssystem versucht die für die Prozesse nötigen Daten immer im Hauptspeicher zu haben, da die Zugriffszeit dort sehr viel kleiner ist, als auf der Festplatte. Dieser ist jedoch nicht beliebig groß, daher müssen einige Strategien befolgt werden, um Prozesse ein- und auszulagern. Solange die für den Prozess benötigten Daten nicht eingelagert sind, kann der Prozess nicht ausgeführt werden.
Hier werden Prozesse komplett aus- und eingelagert. Hierzu wird auf der Festplatte ein bestimmter Bereich reserviert, der sog. „Swap-space”. Ein Prozess wird ausgelagert, wenn:
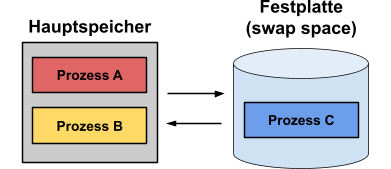
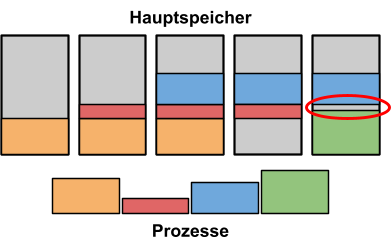
Hierbei kann es zu kleinen, ungenutzten Bereichen im Hauptspeicher kommen, da die Prozesse nicht immer die vorhandenen „Lücken” komplett ausfüllen:
Hauptspeicher und externer Speicher (z.B. Festplatte) werden so vereint, dass sie wie ein einzelner, großer Speicher wirken.
Es gibt hier mehr Adressen, als es im Hauptspeicher gibt, daher wird dieser Speicher „Virtueller Speicher” genannt.
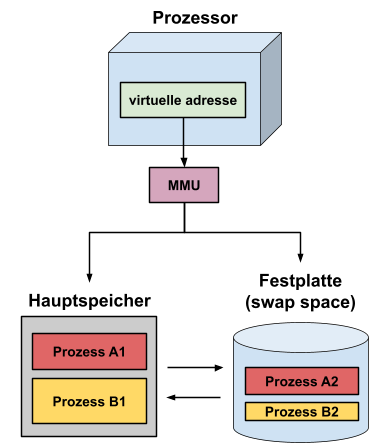
Der Prozess wird in mehrere Teile aufgeteilt. Der Teil des Prozesses, der gerade benötigt wird, steht im Hauptspeicher, der Rest wird ausgelagert.
Es kann also auch nur ein Teil des Prozesses im Hauptspeicher stehen.
Wenn der Prozess auf einen Teil zugreift, der aktuell auf der Festplatte liegt, muss dieser erst eingelagert werden.
Dies übernimmt die MMU (Memory Management Unit = Speicherverwaltungseinheit): Sie weiß, ob ein Teil ein- oder ausgelagert ist.
Wenn auf einen nicht eingelagerten Teil zugegriffen wird, wird dieser eingelagert und die Adresse in der MMU aktualisiert.
So müssen sich die Programme keine Gedanken machen, wo die einzulesende/beschreibende Adresse liegt, sondern sie können eine virtuelle Adresse verwenden,
die immer gleich bleibt, während die MMU die dazugehörigen realen, sich verändernden Adressen im Hintergrund passend verwaltet.
Dies hat mehrere Vorteile: Die Größe des Prozesses ist nicht auf die des Hauptspeichers begrenzt und es können mehrere Programme gleichzeitig ausgeführt werden,
die in ihrer Gesamtlänge den Hauptspeicher überschreiten würden.
Es gibt zwei verschiedene Möglichkeiten, diese Variante zu implementieren:
Segmentorientierter Speicher
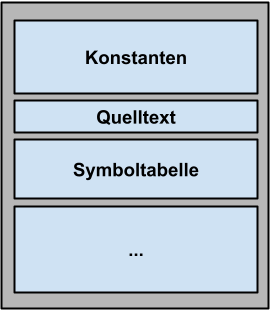
Der Adressraum wird hier in Abschnitte (Segmente) variabler Größe eingeteilt, die den logischen Einheiten des Prozesses entsprechen,
z.B: Quelltext, Konstanten oder die Symboltabelle. Diese besitzen je eine Segmentnummer, welche in einer Segmenttabelle verwaltet werden.
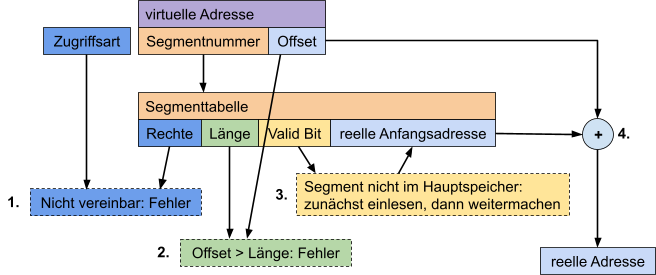
Diese Tabelle enthält für jedes Segment folgende Attribute:
| Rechte | Länge | Valid Bit | reelle Anfangsadresse |
|---|
Die Rechte beschreiben, auf welche Art auf das Segment zugegriffen werden darf, die Länge beschreibt die Länge des Segments, das Valid Bit sagt aus,
ob sich das Segment bereits im Hauptspeicher befindet (1 = ja; 0 = nein) und die reelle Anfangsadresse ist, wenn es sich im Hauptspeicher befindet,
die Startadresse des Segments im Hauptspeicher; wenn es nicht im Hauptspeicher ist, dann sagt es aus, wo es auf der Festplatte zu finden ist.
Die virtuelle Adresse, also die, die der Prozess anfordert,
besteht aus der Segmentnummer und dem Offset innerhalb des Segments.
Ein kompletter Zugriff auf eine virtuelle Adresse sieht folgendermaßen aus:
| Vorteile | Nachteile |
|---|---|
| Segmente lassen sich individuell mit Rechten schützen | Möglicherweise sehr große Segmente, die zusammenhängend gespeichert werden müssen |
| Segmente können dynamisch größer und kleiner werden | Bei Zugriff auf Segment muss ganzes Segment eingelesen werden, obwohl vielleicht nur ein kleiner Teil benötigt wird |
Seitenorientierter Speicher (Paging)
Der virtuelle und physische Speicher wird beim Paging in gleich große, je zusammenhängende Teile eingeteilt. Die virtuellen Teile werden Seiten genannt,
die physischen Seitenrahmen / Pageframes / Kacheln / Tiles. Um Seiten und Seitenrahmen zueinander zuordnen zu können, wird, ähnlich wie bei dem segmentorientieren Speicher,
eine Seitentabelle (Page Table) verwendet. Jeder Prozess besitzt eine solche Tabelle. Die virtuelle Adresse besteht auch hier aus Seitennummer und Offset.
Ein Beispiel zur Adressberechnung:
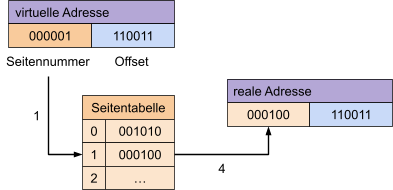
Natürlich muss, wie beim Segmentorientieren, überprüft werden, ob die Zugriffsrechte stimmen, die Länge überschritten wurde und ob das Valid Bit gesetzt ist
(wenn nicht: Seite einlesen, Adressen aktualisieren und weitermachen).
| Vorteile | Nachteile |
|---|---|
| Einfachheit: Alle Seiten haben die gleiche Länge, es treten keine Verschnittprobleme auf. Die Seiten können beliebig ausgetauscht werden | Struktur des virtuellen Speichers spiegelt nicht den logischen Aufbau wieder (alle Daten durcheinander; nicht in Segmente eingeteilt) |
| Es müssen nicht große Teile eingelesen werden, wenn nur ein kleiner von diesen gebraucht wird | Speicherplatz wird womöglich verschwendet, wenn eine Seite nicht komplett voll beschrieben wird |
| Hoher Speicherbedarf für die Seitentabellen |
